
はじめに¶
Springerが書籍PDFを無料公開してくれている(2020/05/09現在).およそ400冊の専門書をタダで手に入れることができるという願ってもない機会だ.
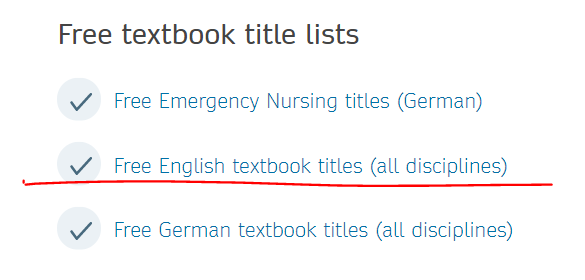
上のリンク先の最後の方に,Free English textbook titles (all disciplines) というリンクがあり,無料公開PDFの一覧excelファイルを入手できる.

このexcelファイルに各書籍PDFのダウンロードリンクが記載されているのだが,複数のファイルをひとつずつ手作業でダウンロードするのはめんどくさい.
そこで,一括ダウンロードするコードを書いた.
コード¶
まず,上のリンクから無料公開PDFの一覧excelファイルをダウンロードする.
おそらくFree+English+textbooks.xlsxというファイル名になっている.適当なワーキングディレクトリで中身を確認する.
In [1]:
# required module : pandas, urllib, re, time
import pandas as pd
import urllib
import re
import time
excel_path = 'Free+English+textbooks.xlsx'
df = pd.read_excel(excel_path)
df.head(3)
Out[1]:
約400冊(ファイル)あるので欲しいものだけ残した(行を削除した)excelファイル(
NEW_Free+English+textbooks.xlsx)を作成する.もちろん約400冊すべてダウンロード,行を間引く編集の必要はない.
さらに,pdfという名前のディレクトリを作成しておいて,以下のコードを実行すれば一括ダウンロードできる.
(※)注意点
- 最初は数ファイルでお試しで実行してください
- ダウンロードリクエストは適度に間隔をあけてください(下のコードでは10秒に設定している)
- ファイル名は,
YYYY_Title.pdfという形式にしているがお好みで変更してください
In [2]:
New_excel_path = 'New_Free+English+textbooks.xlsx'
New_df = pd.read_excel(New_excel_path)
N = New_df.shape[0]
for i in range(N):
time.sleep(10) # Manner
download_URL = 'https://link.springer.com/content/pdf/' + New_df['DOI URL'][i].split('http://doi.org')[1] + '.pdf'
editoin = New_df['Edition'][i]
year = re.findall('\d{4}', editoin)[0]
title = New_df['Book Title'][i].replace(' ', '_')
file_name = 'pdf\\' + year + '_' + title + '.pdf'
urllib.request.urlretrieve(download_URL, file_name)
おわりに¶
無料公開してくれる著者およびSpringerに感謝し,サーバーに負荷をかける極端なリクエストは避けましょう.